
JAVA 진영에서의 ORM 표준 기술인 JPA의 필요성은 여러 자료를 통해 머리로는 대충 알고 있었지만, 영한님 설명을 통해 좀 더 와닿게 되었다
1. 상속

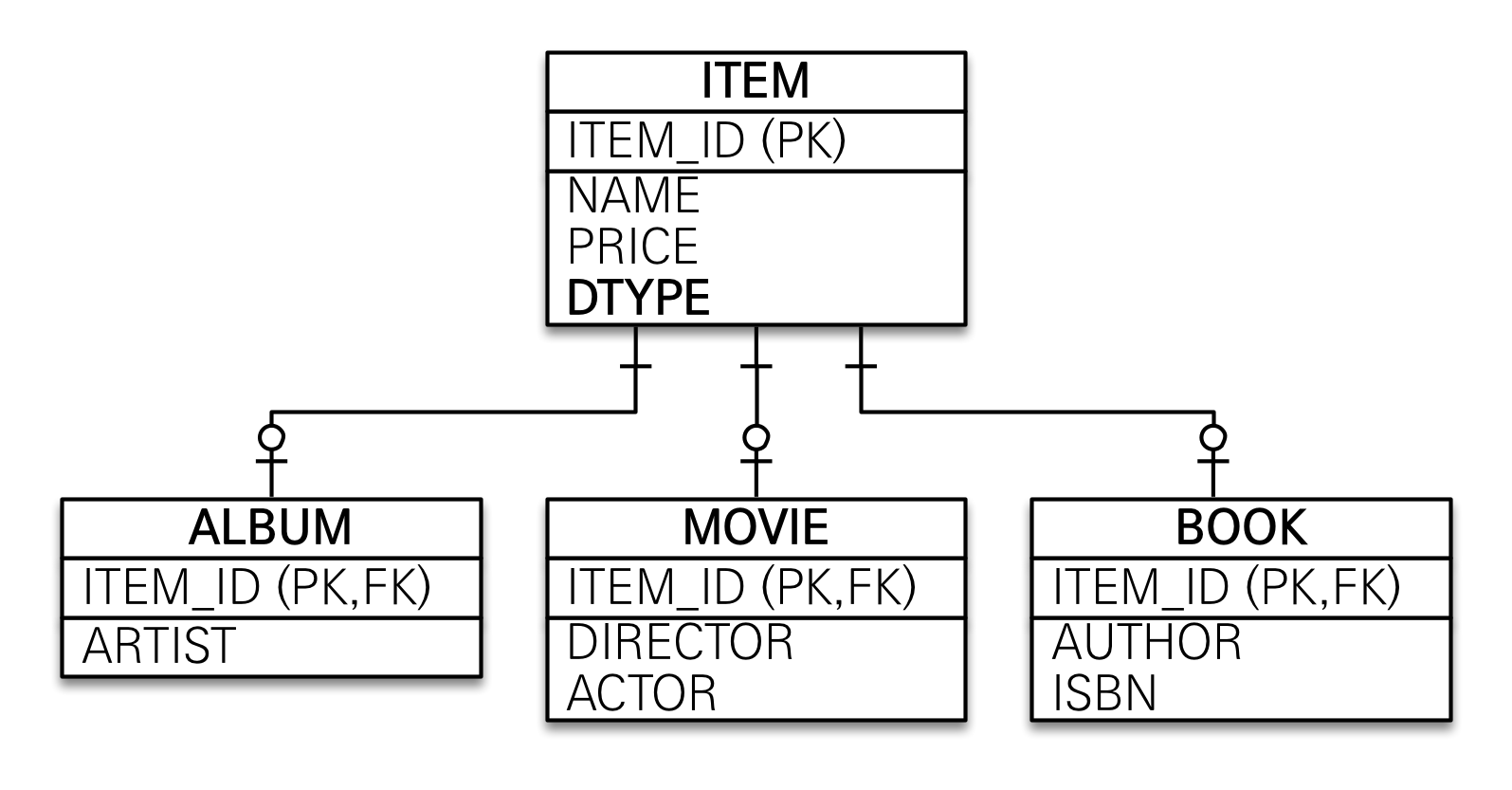
- Item 객체를 상속받은 Album 객체를 RDB에 저장할 때 앨범을 필드단위로 분해하여 우측의 ITEM, ALBUM 테이블에 각각 적절하게 저장해주기 위해 INSERT SQL문도 각각 작성하여 두번 날려야 한다
- DB에서 ALBUM 객체를 조회할 때는 우측의 ITEM, ALBUM 테이블을 JOIN SQL문으로 묶어주고 그것을 다시 객체로 매핑해준 후 반환한다
- 이렇게 SQL 의존적이고 복잡한 과정을 피하기 위해 DB에 저장할 객체에는 상속관계를 사용하지 않게 된다고 한다
2. 연관관계
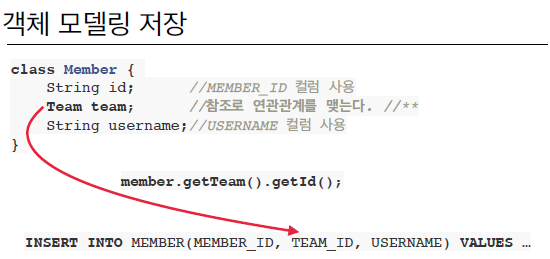

- 객체 지향적으로 모델링하는 경우에 저장할 때는 크게 문제가 없다
- 대신 조회할 때는 MEMBER와 TEAM을 조인한 테이블에서 자바 객체인 Member와 Team의 필드에 해당하는 값들에 일일히 매핑해준 후 member 인스턴스에 team 인스턴스와의 연관관계를 세팅해주면 최종적으로 그 member를 반환
3. 처음 실행하는 SQL문에 따라 탐색 범위가 결정되므로 엔티티 신뢰 문제 발생 -> 진정한 계층 분할이 어려움
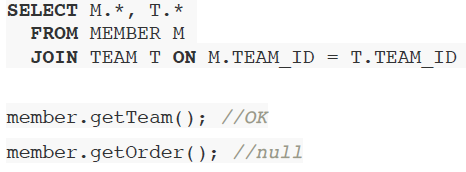
4. 같은 ID값으로 조회한 두 객체에 대해 == 연산에 차이가 있다
- DB에서 조회하면 SQL문 이후 new로 새로 생성하여 반환하기 때문에 == 연산 결과 false가 나오고
- 자바 컬렉션에서 조회하면 같은 객체를 참조할 것이기 때문에 true로 나올 것이다
이렇게 객체와 SQL 간의 불일치가 많기 때문에
객체답게 모델링 할수록 매핑 작업만 늘어난다
JPA와 패러다임의 불일치 해결
1. 상속
- 저장
- 개발자: jpa.persist(album);
- JPA: INSERT SQL문 두번 작성하여 저장 처리 해줌
- 조회
- 개발자: Album album = jpa.find(Album.class, albumId);
- JPA: 앨범 객체를 구성하는데 필요한 데이터를 JOIN SQL문을 통해 가져와서 매핑해준 뒤 반환
2. 연관관계

- 자바 컬렉션에 저장하고 조회하듯이 setTeam()과 getTeam() 사용하여 처리 가능
3. 신뢰할 수 있는 엔티티, 계층 (지연로딩) -> 자유롭게 객체 그래프 탐색
4. 동일한 트랜잭션에서 조회한 엔티티는 같음을 보장
JPA의 성능 최적화 기능
1. 1차 캐시: 한 트랜잭션 내에서는 같은 엔티티를 반환하기 때문에 캐싱 효과가 있음
2. 트랜잭션을 지원하는 쓰기 지연

- 세 멤버를 DB에 저장하는데 독립적으로 수행하면 네트워크를 세번 왔다갔다 하기 때문에 낭비일 수 있다
- JDBC BATCH SQL 기능을 직접 구현하려면 매우 복잡한데, JPA가 이를 편하게 사용하게끔 해준다
- 비슷한 쿼리들을 모아서 한번에 네트워크에 보낼 수 있음
3. 지연 로딩
- 지연 로딩: 객체가 실제 사용될 때 로딩 (프록시 활용)
- Member를 조회할 때 Team은 대부분 필요없다면 지연로딩이 유리
- 즉시 로딩: JOIN SQL문 실행 시에 미리 모두 로딩
- Member를 조회할 때 대부분 Team도 같이 조회한다면 즉시로딩이 유리
- 두 가지 로딩 옵션을 쉽게 설정할 수 있음

출처: 인프런 김영한님 JPA 프로그래밍 - 기본편
'course > inflearn' 카테고리의 다른 글
| [JPA 프로그래밍 기본편] 영속성 관리 (0) | 2022.08.30 |
|---|---|
| [JPA 프로그래밍 기본편] JPA 시작하기 (0) | 2022.08.30 |
| [HTTP 웹 기본 지식] (0) | 2022.07.29 |
| [스프링 입문] (0) | 2022.07.29 |
| [만들어 가면서 배우는 JAVA 플레이그라운드] 캘린더 (0) | 2022.07.18 |